쿠버네티스에 대한 관심이 생기며 CKA란 자격증도 알게 됐다. 원랜 개발 관련한 자격증은 막연한 편견이 있었다. 실무와 거리가 멀것만 같은… 하지만 시험이 프롬프트를 통해 쿠버네티스 상태를 만든다는 점에서 그런 편견이 깨졌다. 무엇보다 회사에서 아직 쿠버네티스를 쓰지 않으니 배울 수 있는 좋은 기회인거 같아 자격증 준비를 시작했다.
아주 유명한 Udemy 강의인 Certified Kubernetes Administrator (CKA) with Practice Tests를 듣고 있다. 강의를 들은 후 섹션별로 내용을 정리할 계획이다.
쿠버네티스 문서화가 잘 되어 있고 한글 번역된것도 많다. 강의를 보고 더 궁금한 내용은 문서를 참고해서 보강했다.
Cluster Architecture
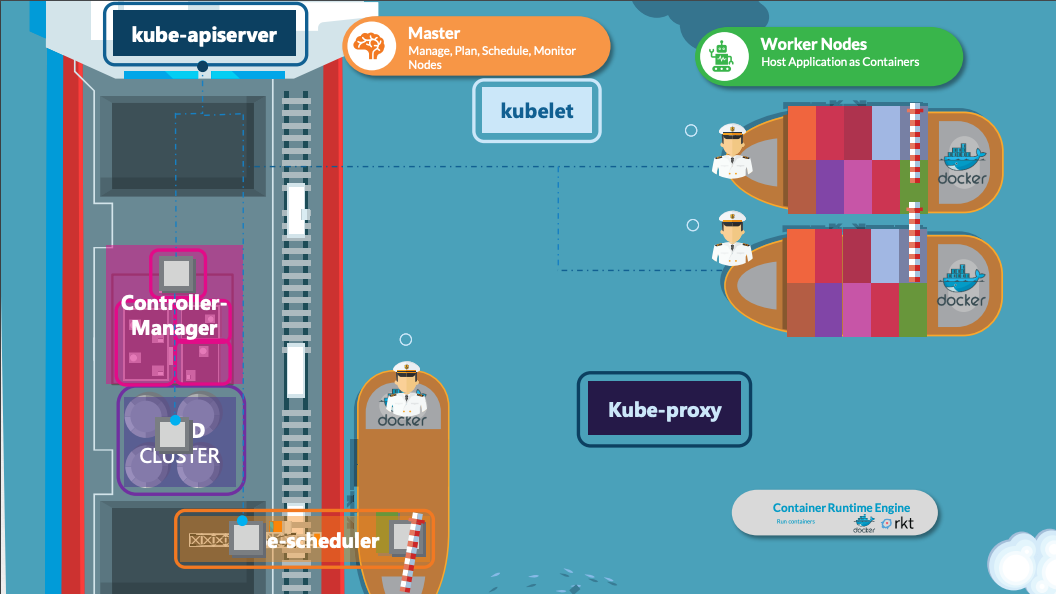
위 그림은 쿠버네티스 클러스터 기본적인 구조를 보여준다. 클러스터는 크게 마스터와 워커 노드로 나뉜다. 마스터의 컴포넌트부터 살펴보자.
* 문서에선 마스터 대신 컨트롤 플레인이라는 용어를 사용한다. kodekloud에서 문제를 할 때도 프롬프트 이름이 controlplane이다.
Etcd
(엣씨디라고 읽는다!) key value 저장소로 클러스터의 모든 데이터를 저장하고 있다. 예를 들어 kubectl get ... 명령을 하면 etcd에 접근해 데이터를 가져온다. 고가용성(multimaster)를 지원한다.
Kube-apiserver
마스터의 다른 컴포넌트 뿐만 아니라 노드와도 통신한다. 유일하게 etcd에 직접 접근하는 컴포넌트이다. 따라서 모든 컴포넌트가 서로 통신할 때 거쳐가게 된다. 앞서 kubectl get ... 같은 명령도 이 API 서버를 호출하는 것이다.
Kube-controller-manager
클러스터 내 여러 컨트롤러가 있고, 모든 컨트롤러가 모여 있는 프로세스이다(컨트롤러는 논리적으론 각각의 프로세스지만 복잡성을 낮추기 위해 이 매니저 프로세스 하나로 실행된다고 한다). 컨트롤러의 역할은 크게 두가지이다:
- Watch status
- Remediate situation
즉, 특정 기능이 수행하도록 컴포넌트 상태를 모니터하고 관리하는 프로세스이다. 예를 들어, 는 노드 컨트롤러 노드의 상태를 보고 unreachable이면 해당 노드에서 파드를 방출하고 다른 노드에 파드를 할당 후 프로비저닝 하는 역할이다. 다음 같은 컨트롤러가 더 있다:
- 레플리케이션 컨트롤러
- 엔드포인트 컨트롤러
- 서비스 어카운트 & 토큰 컨트롤러
Kube-scheduler
새로 생성된 파드를 어떤 노드에 적재할지 선택하는 컴포넌트다. 파드에 대한 노드의 수용력(capacity)과 필요한 리소스가 있는지를 확인한다. 기본적으로 필터링하고 우선순위 함수로 노드를 랭킹한다고 한다. 테인트와 톨러레이션, 어피니티 같은 개념도 사용한다는데 이는 뒤에서 자세히 다룬다.
Kubelet
지금부턴 노트 컴포넌트다. 쿠블릿은 노드에 컨테이너 적재를 담당한다. 위 그림에선 배의 함장에 비유했다.
Kube proxy
노드의 네트워크 프록시이다. 먼저 쿠버네티스의 네트워크는 파드(또는 여러 파드)를 IP로 노출시키는 ‘서비스’란 노출시켜서 통신하는데, 프록시는 서비스 디스커버리 역할을 한다. 프록시는 대몬셋으로 배포되어 모든 노드에 하나씩 있다. kubectl get daemonset -n <ns>로 확인해볼 수 있다.
워크로드와 서비스
워크로드는 쿠버네티스에서 실행되는 애플리케이션이다. 워크로드는 컨테이너를 실행하는 파드와 이 파드를 관리하는 워크로드 리소스로 이루어져 있다. 또 앞에서도 언급했지만 애플리케이션, 즉 파드는 서비스로 노출되어 클러스터에서 통신한다. 다음은 파드와 몇가지 워크로드 리소스, 그리고 서비스에 대해서 알아본다.
파드
파드는 애플리케이션 인스턴스이다. 애플리케이션 실행을 위해 컨테이너가 하나일수도 있지만 여러개일수도 있다. 예를 들어 웹 서버인 nginx와 웹앱 서버인 유니콘을 하나의 애플리케이션으로 본다면(적절한가?) nginx와 유니콘 두개의 컨테이너를 한 파드로 묶을 수 있다. 파드 내에서 컨테이너들은 저장소나 네트워크 같은 자원을 공유한다.
레플리카셋
파드를 다중화하여 고가용성을 보장하는 워크로드 리소스이다. 파드의 복제본이 몇개인지 정의하여 관리할 수 있도록 한다. 원랜 이 책임이 앞서 말한 레플리케이션 컨트롤러에게 있었던거 같지만 지금은 컨트롤러 대신 레플리카셋을 쓰도록 권장한다.
디플로이먼트
파드를 배포한다. 애플리케이션의 롤링 업그레이드, 롤백 등을 정의 할 수 있다. 레플리카도 정의할 수 있어서 위의 레플리카셋의 기능도 하며 더 권장하는 방법이다.
서비스
파드, 즉 애플리케이션끼리 또는 클러스터 외부로 통신할 수 있게 해주는 오브젝트이다. 타입은 다음 세가지가 있다:
- ClusterIP: 기본 타입. 같은 레이블의 여러 파드를 하나의 IP로 노출
- NodePort: 세개의 포트 키를 정의하여 서비스에서 클러스터 외부까지 포트포워딩 역할을 한다
- targetPort: 파드의 포트
- port: 서비스 포트
- nodePort: 클러스터 외부에 노출하는 포트(30000 -32767)
- LoadBalancer: 네이티브 클라우드 로드밸런서를 사용하기 위함. 클라우드 환경에서만 동작. 아닌 곳에선 NodePort 처럼 동작
오브젝트
서비스를 설명하며 오브젝트라는 말을 썼다. 파드는 워크로드 단위, 레플리카셋과 디플로이먼트는 워크로드 리소스 그리고 서비스는 네트워크 단위로 각각 용도가 다르지만 모두 오브젝트이다.
오브젝트란 쿠버네티스가 상태를 나타내는 것이다. 우리가 YAML로 오브젝트를 정의하면 쿠버네티스는 YAML과 클러스터는 같은 상태가 유지되도록 노력한다. 문서에선 오브젝트를 “의도를 담은 레코드"라고도 표현한다.
오브젝트 YAML엔 다음 네개 필수 필드가 있다:
- apiVersion: 오브젝트 생성을 위한 쿠버네티스 API 버전
- kind: 오브젝트 종류
- metadata: 오브젝트를 식별하는 데이터
- spec: 의도한 오브젝트 상태를 기술
네임스페이스
이런 오브젝트를 격리하는 단위가 네임스페이스이다. 예를 들어 개발 시 Dev, Production에 해당하는 네임스페이스를 각각 두고 리소스(오브젝트)를 배치할 수 있다.
kubectl config current-context 명령으로 현재 사용중인 네임스페이스를 볼 수 있고, kubectl set-context $(kubectl config current-context) --namespace=<ns>로 네임스페이스를 <ns>로 바꿀 수 있다.
Imperative vs. Declarative
쿠버네티스 클러스터는 시스템 아키텍처라고 볼 수 있을 것이다(시험 볼때 말고…). 아키텍처를 정의하는데 IaC(논리적인 인프라라고 치자)로 유명한 두 방법에 대한 이야기다.
쿠버네티스는 명령적 그리고 선언적 방법을 둘다 제공한다. 명령적 방법은 kubectl의 CRUD 명령을 통해 API를 호출하는 것이고, 선언적 방법은 오브젝트를 YAML로 선언한 후 kubectl apply 하는 것이다.
당연히 선언적 방법이 큰 규모 시스템일수록 관리에 유리하다고 여겨질테지만, 시험에선 시간을 아끼는 방법으로 명령적 방법도 익혀 사용할 것을 권장한다. 실제 일할 때도 긴급한 상황에선 명령적 방법이 도움이 될지도 모르겠다.
Kubectl apply
선언적 방법, 즉 kubectl apply이 파일 변경을 반영은 패치 병합을 통해 한다. 새로 적용하려는 오브젝트 설정(yaml)와 현재 구동 중인 설정의 diff를 적용한 상태로 만든다. 이때 새로 반영한 설정은 last-applied-configuration란 어노테이션(메타데이터 중 하나이다)에 저장된다. 그렇다면 diff를 병합할 때도 그 이전에 기록된 last-applied-configuration와 비교했을 것이다. 문서의 예제를 참고하자.
last-applied-configuration 값은 JSON으로 저장된다(똑같이 YAML로 하면 키 충돌이 있을지도 모르겠다).