사내에서 Elasticsearch 스터디를 진행 중이다. 특히 키바나(쿼리와 시각화)를 더 잘 쓰고 싶어서 이 주제를 하자고 주장했다. 그런데 우리가 스터디 하는 2~3개월 정도 기간에 가이드가 될만한 책이나 강의가 마땅치 않아, 스터디 진행 구성도 오밀조밀하게 직접했다. 그중 첫단계는 Elastic 가이드 북을 한번 읽는 것인데 이제 막 끝났다.
일단 너무 재밌었다. 내가 알고 싶었던 것은, match 쿼리 결과가 왜 생각하는대로 안나오는지, terms aggregation에 왜 이런 결과가 있는지, 같은 것인데 이를 다 해소할 수 있었다. 더욱이, 작년에 정말 재밌게 읽은(그리고 이것 마저 안했으면 작년엔 아무 소득이 없을뻔 했다고 느끼는..) DDIA의 내용을 다시 떠올리게 하는 것도 있어서 좋았다.
정확히 말하면 DDIA 3장의 내용인데 나는 이 3장에서 처음 나와 책의 끝까지 중요한 개념인, 추가 전용 로그(append-only log)를 엔진으로 쓰는 DB, 그리고 칼럼 지향 저장소(columnar storage)를 멋진 개념이라고 생각만했다. 막상 쓸 일은 없겠다고 느꼈는데 설치하여 잘 쓰고 있는 Elasticsearch가 그런 DB였던 것이다..😱
이 글은 기본적으론 위 가이드북의 순서를 따르되 중간중간 생략하는 부분이 많을 것이다. DDIA 3장 이외의 내용도 들어간다. 또 Elasticsearch 관련해선 가이드북 바깥으로 확장되는 설명도 있을 것이다.
샤드와 노드 구성
가이드북 3.2 인덱스와 샤드 - Index & Shards과 3.3 마스터 노드와 데이터 노드 - Master & Data Nodes 관련한 내용이다. DDIA 3장과는 크게 관련 없다. 하지만 DevOps로서 안 짚고 넘어갈 수 없는 부분이다.
샤드와 노드는 각각 고가용성을 위해 복제본을 둔다. 특히 샤드는 노드 수가 큰 영향을 끼친다. 같은 샤드의 프라이머리랑 복제본이 같은 노드에 있을 경우, 노드가 유실됐을 때 샤드를 복구할 방법이 없기 때문이다.
노드는 Split brain을 방지하기 위해 discovery.zen.minimum_master_nodes 값을 설정한다. 마스터 노드 후보 개수가 n일 때, (n / 2) + 1 개로 설정하길 권장하며 n은 홀수가 되어야 한다고 한다. 이는 DDIA 5장에서 처음 나와 분산 컴퓨팅 합의 알고리즘에서 사용하는 정족수에 대한 내용과 일치한다(하지만 실제로 회사에서 적용할 필요 없을만큼 적은 노드를 운용중이다 ㅎㅎ).
로컬 실습 구성
가이드북 4장부턴 예시 데이터와 쿼리를 실습하면 좋다. 또 이 글은 연습문제 형식이 아니지만 생략이 많아 궁금증을 유발하는게 꽤 있을거 같다. 맥 기준으로 docker compose와 쿠버네티스 설정 파일을 공유한다. 가이드북의 예제를 따라 해보길:
# docker-compose
version: '3'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.15.2
container_name: elasticsearch
environment:
- node.name=es
- discovery.type=single-node
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- ./data:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
kibana:
image: docker.elastic.co/kibana/kibana:7.15.2
container_name: kibana
ports:
- 5601:5601
networks:
- elastic
networks:
elastic:
driver: bridge
apiVersion: v1
items:
- apiVersion: v1
kind: Service
metadata:
annotations:
kompose.cmd: kompose convert -f elk-compose.yml --out elk-definition.yml
kompose.version: 1.26.0 (HEAD)
creationTimestamp: null
labels:
io.kompose.service: elasticsearch
name: elasticsearch
spec:
ports:
- name: "9200"
port: 9200
targetPort: 9200
selector:
io.kompose.service: elasticsearch
status:
loadBalancer: {}
- apiVersion: v1
kind: Service
metadata:
annotations:
kompose.cmd: kompose convert -f elk-compose.yml --out elk-definition.yml
kompose.version: 1.26.0 (HEAD)
creationTimestamp: null
labels:
io.kompose.service: kibana
name: kibana
spec:
type: NodePort
ports:
- name: "5601"
port: 5601
targetPort: 5601
nodePort: 30561
selector:
io.kompose.service: kibana
status:
loadBalancer: {}
- apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
kompose.cmd: kompose convert -f elk-compose.yml --out elk-definition.yml
kompose.version: 1.26.0 (HEAD)
creationTimestamp: null
labels:
io.kompose.service: elasticsearch
name: elasticsearch
spec:
replicas: 1
selector:
matchLabels:
io.kompose.service: elasticsearch
strategy:
type: Recreate
template:
metadata:
annotations:
kompose.cmd: kompose convert -f elk-compose.yml --out elk-definition.yml
kompose.version: 1.26.0 (HEAD)
creationTimestamp: null
labels:
io.kompose.network/elastic: "true"
io.kompose.service: elasticsearch
spec:
containers:
- env:
- name: ES_JAVA_OPTS
value: -Xms512m -Xmx512m
- name: bootstrap.memory_lock
value: "true"
- name: discovery.type
value: single-node
- name: node.name
value: es
image: docker.elastic.co/elasticsearch/elasticsearch:7.15.2
name: elasticsearch
ports:
- containerPort: 9200
resources: {}
volumeMounts:
- mountPath: /usr/share/elasticsearch/data
name: elasticsearch-claim0
restartPolicy: Always
volumes:
- name: elasticsearch-claim0
persistentVolumeClaim:
claimName: elasticsearch-claim0
status: {}
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
creationTimestamp: null
labels:
io.kompose.service: elasticsearch-claim0
name: elasticsearch-claim0
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Mi
status: {}
- apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
creationTimestamp: null
name: elastic
spec:
ingress:
- from:
- podSelector:
matchLabels:
io.kompose.network/elastic: "true"
podSelector:
matchLabels:
io.kompose.network/elastic: "true"
- apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
kompose.cmd: kompose convert -f elk-compose.yml --out elk-definition.yml
kompose.version: 1.26.0 (HEAD)
creationTimestamp: null
labels:
io.kompose.service: kibana
name: kibana
spec:
replicas: 1
selector:
matchLabels:
io.kompose.service: kibana
strategy: {}
template:
metadata:
annotations:
kompose.cmd: kompose convert -f elk-compose.yml --out elk-definition.yml
kompose.version: 1.26.0 (HEAD)
creationTimestamp: null
labels:
io.kompose.network/elastic: "true"
io.kompose.service: kibana
spec:
containers:
- image: docker.elastic.co/kibana/kibana:7.15.2
name: kibana
ports:
- containerPort: 5601
resources: {}
restartPolicy: Always
status: {}
kind: List
metadata: {}
각각 localhost:5601과 <service_ip>:30561으로 키바나 접속할 수 있다.
전문 검색과 match 쿼리
먼저 Elasticsearch가 전문 검색(full-text search)용 DB라는 점을 알고 있어야 한다. 이를 위해 역인덱스라는 인덱스 방법을 쓴다. 역인덱스는 전문 필드를 텀(term)으로 나누고 각 텀에 해당하는 문서를 유지하여 빨리 검색하게 도와준다. 대략 그림처럼 문서들을 인덱스로 관리한다고 생각하면 된다(애널라이저 설명은 생략한다):

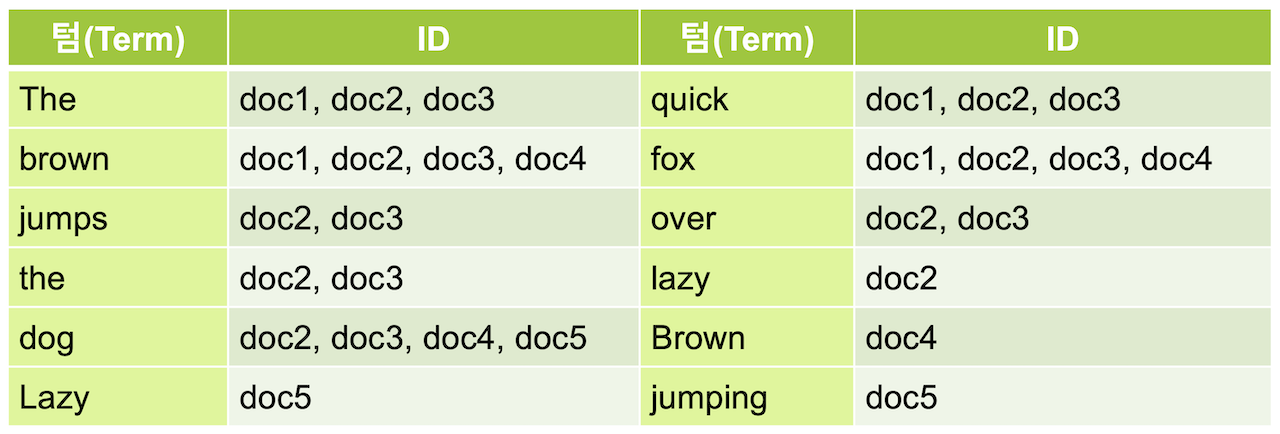
따라서 “match”: “quick” 같은 쿼리로 검색하면 문서 doc1, doc2, doc3를 바로 가져온다. 하지만 “match”: “quick dog"으로 검색하면 doc1~5의 모든 문서를 가져온다. 이는 역인덱스 기준으로 quick과 dog 텀의 union이다. match 쿼리가 기본적으로 공백 같은 구분자에 대해 텀을 나누고 OR 연산하기 때문이다.
위에선 예시를 하나 들었지만, Elasticsearch가 데이터를 다루는 방식과 그에 맞게 잘 검색하기 위해선 5. 검색과 쿼리 - Query DSL와 6. 데이터 색인과 텍스트 분석는 꼭 다 읽어보면 좋다. 가이드북에선 띄어쓰기를 포함한 “quick dog"이라는 글자 자체에 대한 검색 방법이나, “quick"과 “dog"를 둘 다 포함하는 문서를 검색하는 방법에 대해서도 알 수 있다.
렐러번트와 렐러번트 무시하기
회사에선 Elasticsearch를 전문 검색보단 로그를 수집하여 모니터하는데 쓰기 때문에 필드가 자연어 전문이 아닌 경우가 대부분이다. 그럼에도 Elasticsearch가 데이터를 어떻게 저장하고 검색 시 어떻게 반환하는가를 아는 것이 많이 도움이 된다.
특히 SQL에 빗대어 속성 과외식으로 표현하는건 아주 무의한거 같다. 가이드북도 이를 알고 있는지 5.2 Bool 복합 쿼리 - Bool Query에서 그걸 인용하지만… 뒤에 이어지는 5.3 정확도 - Relevancy에서 스코어 즉, 렐러번트 개념을 이해하는게 더 중요한거 같다. 딱봐도 복잡한 BM25 수식을 이해할 필욘 없다. TD-IDF와 필드 길이의 시맨틱을 이해하고 예제 데이터를 쿼리하여 결과를 찍어 스코어를 보는 것으로 충분하다(필드 길이는 시맨틱을 이해할 필요도 없겠다). 나는 다음처럼 기대하고 스코어가 그에 맞게 바뀌는지 여러번 쿼리해봤다:
- 문서에서 단어가 많이 반복되면 스코어 올라간다(TF).
- 전체 문서에(corpus) 단어가 많이 등장하면 스코어가 내려간다(IDF).
- 필드 길이가 길어지면 스코어가 내려간다.
음…쓰고나니 TF와 IDF도 이름에 따라 자명한 해석이다(오히려 시맨틱으로 이해하자고 말한게 더 헷갈렸을거 같다). 물론 잘난척(“쉬운데?")은 아니다. 나는 얼마전에 TF-IDF 인코딩을 할 일이 있어 좀 더 익숙했을 뿐이다…
렐러번트 역시, 카디널리티가 꽤 낮은, 회사의 로그 필드에 대해선 사용할 기회가 많지 않을거 같다. 그래서 로그를 찾을 땐 스코어링 하지 않고 filter 쿼리만 쓰게 되었다(5.5 정확값 쿼리 - Exact Value Query).
집계가 왜 그렇게 빨라?
집계(aggregation)은 정말 좋아하는 Elasticsearch 기능이다. 몇 분에 해당하는 로그(=문서)도 엄청나게 많기 때문에 이를 한눈에 보기 위해 자주 이용했다. Elasticsearch의 집계는 엄청 빠르다. 원리에 대해선 고민해보지 않았고 인덱스가 그정도로 크니 그러려니? 했었다.
하지만 가이드북 8.2 버킷 - Bucket Aggregations를 보는 순간..:
...
# 버킷 부분만 잘라 왔다
"buckets" : [
{
"key" : "강남",
"doc_count" : 5
},
{
"key" : "불광",
"doc_count" : 1
},
{
"key" : "신촌",
"doc_count" : 1
},
{
"key" : "양재",
"doc_count" : 1
},
{
"key" : "종각",
"doc_count" : 1
},
{
"key" : "홍제",
"doc_count" : 1
}
]
...
“엇 이건 런렝스 인코딩인데?“라는 생각이 들었고, DDIA 3장을 다시 읽었다. 이 때 Elasticsearch의 스토리지 엔진을 루씬에 기반해서 만들었다는걸 알았다. 그리고 이 포스팅을 읽고 설명해보자면…
Elasticsearch는 모든 필드에 대해 doc_values라는 컬럼 지향(column store) 색인을 구성한다. 이것은 in-memory에서 로그 컴팩션(정렬, 병합)시 불리한 fielddata를 다음과 같은 방법으로 개선한 것이다:
- 모든 데이터를 표현하고 저장할 수 있는 방법의 최소한의 크기로 인코딩하여 저장한다.
- 전문 필드는 정렬된 텀 사전으로 저장한다.
- 숫자(numeric) 필드는 최대공약수로 나누어 나머지만 저장하여 효율을 높인다.
또 런렝스 인코딩과 달리 필드 값이 문서 IDs를 참조하고(B-tree 구조의 세컨더리 인덱스와 비슷하다고 생각했다. 대신 ID 리스트인), 이것을 기반으로 루씬의 나머지 인덱스 컴포넌트인 역인덱스, 텀 벡터 등과 소통하여 결과를 내준다고 한다. 그냥 필드에 대해서만 집계한다면, 런렝스 인코딩처럼, 완전히 컬럼 지향적인 인덱스나 DB만 유지해도 되겠지만 쿼리로 필터를 한 문서에 대해서도 집계 결과가 빠르게 나올 수 있는 이유가 이것이라고 한다.
앞서 언급한 텀 벡터(term vector), 더 정확하게 루씬의 텀 사전(term dictionary)는 추가 전용 로그 DB와 LSM 트리 색인 구조를 사용한다고 한다:
Lucene, an indexing engine for full-text search used by Elasticsearch and Solr, uses a similar method for storing its term dictionary [12, 13]. A full-text index is much more complex than a key-value index but is based on a similar idea: given a word in a search query, find all the documents (web pages, product descriptions, etc.) that mention the word. This is implemented with a key-value structure where the key is a word (a term) and the value is the list of IDs of all the documents that contain the word (the postings list). In Lucene, this mapping from term to postings list is kept in SSTable-like sorted files, which are merged in the background as needed [14].
책에서 설명하던 흐름에선 인덱스가 가리키는 것이 레코드가 아닌 문서 IDs 리스트이기 때문에 ‘유사하다’고 한것 같다. 인덱스 구조 자체는 LSM이라 봐도 될거 같다(루씬에 대해서 더 깊게 찾아보지 않은 것에 대한 변명이다).
DDIA 2회차
Elasticsearch를 스터디하며 추가 전용 로그 DB와 LSM 트리 색인 구현체, 그리고 컬럼 지향 저장소의 장점을 눈으로 확인할 수 있어서 좋았다. 그리고 이런 것이 눈에 들어오게 해준 DDIA는 정말 최고다. 존경의 의미를 담아 DDIA를 한번 더 읽으려고 한다. 다만 이번처럼 상용 DB 예시로 책의 내용을 상기하며 부분부분만 복기하고 싶다.
아마 다음 상용 DB는 MongoDB가 되지 않을까 한다. MongoDB는 레플리카 클러스터 구성과 (failover 상황을 포함한)프라이머리 프로모션할 때 책의 효과를 톡톡히 봤다. 그전에, 딱히 좋은 coordinator가 없는, MariaDB는 장애와 마스터를 zero downtime으로 이전하는데에 애를 먹었다. 하지만 MongoDB는 분산 컴퓨팅에서 합의 프로토콜이 잘 이루어지는거 같았서 DDIA에서 배운 내용이 떠올랐었다.
한편 MongoDB는 저장소나 쿼리, 집계 관련한 부분은 많이 사용하지 못해서 체감할 기회가 없었다. MongoDB 전문 검색 DB도 아니고 인덱스도 명시적으로 생성해주어야 한다. 따라서 인덱스 부분에서만큼은 스키마 설계가 중요한거 같았고, 쿼리, 집계 시에도 JS를 활용하는 유연성이 강점으로 보였다. 즉 검색이나 집계 속도에선 Elasticsearch만큼 빠르진 않지만, 인덱스를 그만큼 유지하진 않을테니 저장 공간과 트레이드 오프가 있을거 같다. MongoDB도 문서를 다루는, 그리고 빠르게 삽입하는 DB인데 추가 전용 로그 방식의 DB가 아닐까 싶다.