https://docs.datadoghq.com/monitors/create/types/outlier/?tab=dbscan
Datadog 모니터에선 기본적으로 한계치 알람(threshold alerts) 기능이 있다. 하지만 다음과 같은 시계열(timeserires) 그래프의 패턴은 알람의 기준을 threshold로 정할 수 없다:
- 스파이크나 아발란체를 예상할 수 있다. 예를 들어 밤 같은 특정 시간대에만 스루풋이 높아져 스파이크가 생긴다면 이는 알람으로 받고 싶지 않다.
- 값의 기준선이 요동친다(fluctuate).
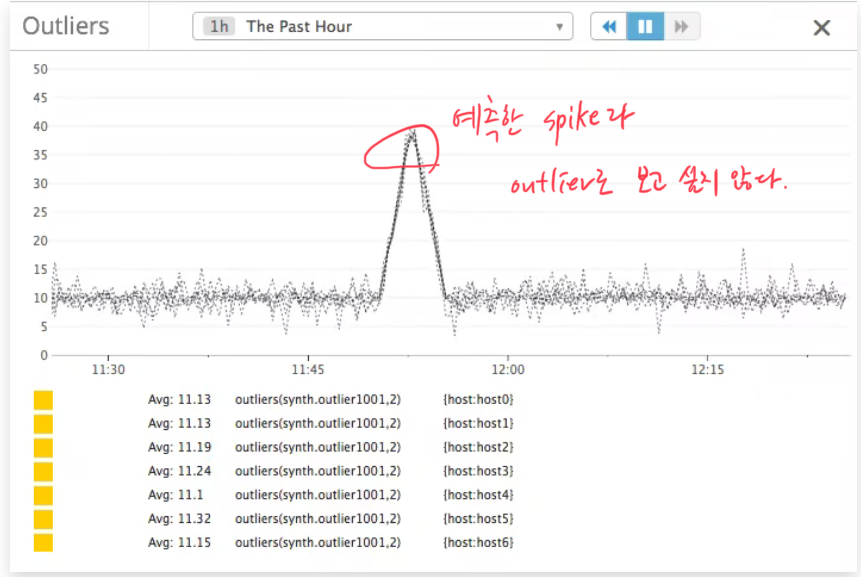 물론 두번째의 경우 threshold 최소, 최대치를 높이는 방법도 생각할 수 있다. 대신 클러스터링 알고리즘과 통계적인 방법으로 이상치를 감지할 수 있다.
물론 두번째의 경우 threshold 최소, 최대치를 높이는 방법도 생각할 수 있다. 대신 클러스터링 알고리즘과 통계적인 방법으로 이상치를 감지할 수 있다.
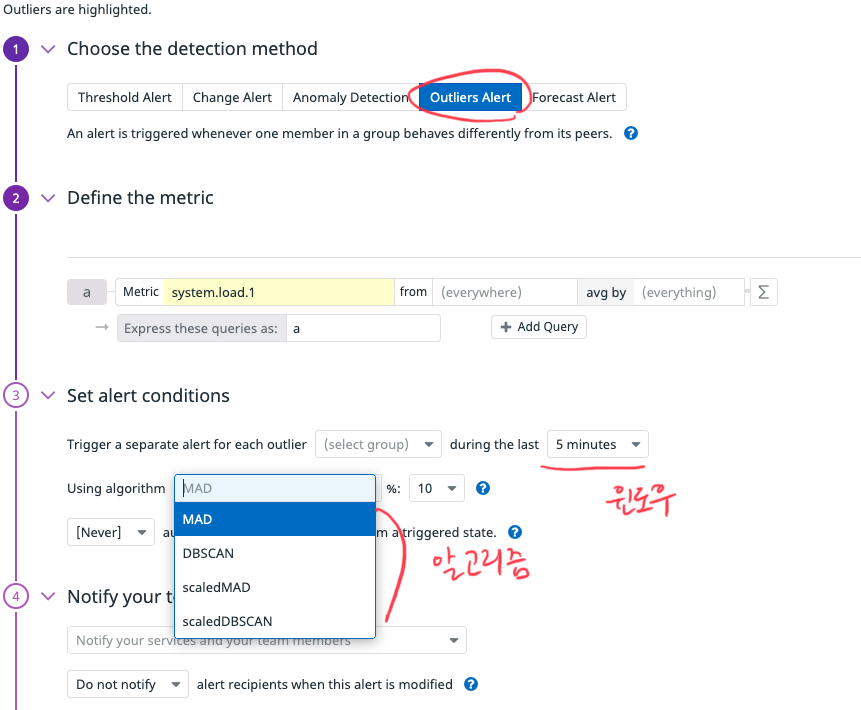
DBSCAN
DBSCAN(Density-Based Spatial Clustering of Appplication with Noise)은 클러스터링 알고리즘이다. 어떻게 군집시킬까(clustering)에 대한 방법인데, 이 포스팅에 잘 설명되어있다. 짧게 정리하면 공간의 어떤 점 p의 반경 epsilon 내에 최소 점의 개수(m) 이상이 있으면 있으면 클러스터가 되고, epsilon 내에 그러한 또 다른 클러스터 중심점이 있으면 두 클러스터는 합쳐진다.
Datadog의 감지 알고리즘으로 DBSCAN을 사용하면 글에서 설명하는 noise pointer를 이상치(outlier)로 감지하여 알람을 보낸다. 그럼 Datadog에선 어떤 공간에서 어떤걸 포인트로 할까? 시계열 그래프에 d개의 요소가 있다면, d-차원 공간에서 각 포인트 간의 유클리디언 거리를 구한다. 이 값이 파라미터인 tolerance라는 값보다 낮으면 클러스터라고 판단한다. 즉, tolerance 바깥 거리에 있는 점들을 이상치 판단한다(tolerance는 epsilon과 비슷한 값이며 후술한다).
그런데 정확히 d개라는 요소가 어떤걸 말하는지 포인트는 어떤 공간에 그려지는건지 모르겠다. 시계열 그래프는 시간과 메트릭 축의 2차원인데 그건 아닌거 같고. d의 요소가 한 라인 그래프를 호스트나 그룹이라면 각각 축의 메트릭 값과 나머지는 0, 시간축의 포인트를 말하는건지… 시각적인 설명이 부족해 정확히 알기 어렵다(아니면 내가 해석을 못한걸수도).
다만 Datadog은 윈도우 내에선 가장 큰 한 클러스터를 만들고 그 클러스터 바깥의 지점을 다 이상치로 판단하고 알람한다. DBSCAN이 2차원에선 어떻게 클러스터링 하는지 이해해서 다차원공간에서 계산한 것이라도 시계열 그래프에 그려진 모양을 보며 어림잡아 이해할 수는 있었다(구현한 Datadog의 코드까진 찾아보지 않았다).
MAD
MAD(Median Absolut Deviation)는 통계치이다. 변동성 있는 데이터에서 강한 측정값(a robust measure)이며 표준 편차의 강한 버전(he robust analogue for standard deviation)이라고 하는데, 찾아보니 강력한 통계(Robust Statistics)라는게 있다… 이것까지 알아보진 않았으나 통계에서 흔히 쓰는 정규화(noramalize)가 잘 안쓰이는 곳에서 먹히는 그런 통계인거 같다.
MAD는 통계치라 비교적 수식으로 쉽게 계산이 된다.
MAD = medain(|Xi -median(X)|)
(hugo template 중 수식 그리는 것 찾아 붙일 것)
중앙값 편차 절대치의 중앙값이다. 표준 편차와 비슷하게도 보여서 익숙하다. 실제로 Datadog 알고리즘으로 계산할 때도 각 포인트에 정규화 상수와 tolerance를 곱하여 계산하기 때문에 정규 분포의 표준 편차에 비견할 수 있다고 한다(사실 나도 느낌만으로 알겠다고 끄덕끄덕했다).
그리고 또 다른 파라미터 pct는 위의 값 바깥으로 나간 이상치가 몇 퍼센트 이상일 때 알람을 보낼지 정하는 threshold이다. 시계열 그래프만 보고도 DBSCAN보다 직관적으로 알고리즘을 이해할 수 있다.
Tolerance와 파라미터
두 알고리즘 모두에 나온 파라미터인 tolerance란 값은 각각
- DBSCAN에선 epsilon에 곱해지는 상수이다. 즉, epsilon x tolerance로 거리 threshold를 만든다.
- MAD에선 위에 설명한듯 MAD에 정규화 상수와 함께 곱해지는 값이다.
두군데서 모두 기본 값이 3.0이다. 더 민감한 알람을 만들고 싶으면 2.5에서 2.0으로 낮추고, 오탐이 잦은것 같으면 4.0, 5.0으로 높이라고 한다. 이상치에 대한 threshold라고 생각하면 곱해지는 상수이니 비례해서 조정하란 이야기다.
MAD의 두번째 파라미터인 pct의 값은 10이다.
또 파라미터는 아니지만 윈도우(during last …) 역시 알고리즘이 적용되는 공간이기 때문에 중요하다. 이것은 그래프 패턴에 따라 정답이 없고 경험으로 터특하는게 중요할 수도 있다.
DBSCAN vs. MAD
Datadog에선 둘 다 거의 비슷한 성능을 낼것이라고 설명한다. 다만 MAD보단 DBSCAN을 써야하는 경우가 있다고 이야기하는데, 다음과 같은 패턴의 그래프이다.
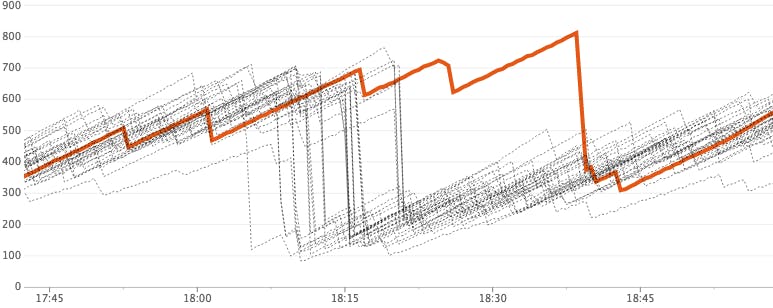
그림은 호스트마다 버퍼가 flush 되는 모양이다. 각각 시간차이가 조금 나지만 패턴은 비슷하다. 이런 경우 위처럼 빨간색으로 이상치로 판단하고 싶지 않은것이다. 이럴때 MAD는 위처럼 이상치로 판단하지만, DBSCAN은 그렇지 않는다고 한다. MAD가 이상치로 판단하는건 이해하기 쉽다. 중앙값에 의존하는데 위처럼 특정 시간대에 같은 패턴이더라도 편차가 큰 경우가 발생할 수 있기 때문이다. DBSCAN은 이러한 양상에서도 클러스터링이 잘 되나보다.
회사에선 보통 모니터 안하던 메트릭을 추가하며 threshold alert만 주로 사용했다. 하지만 주기적 또는 예상이 되는 스파이크가 나온다던가, 기준선이 요동치는 그래프 패턴에서 그런 스파이크나 요동침을 오탐으로 받고 싶지 않을때 단순히 threshold로 커버할 수 없을 땐 outlier alerts를 써보도록 하자. 보통은 DBSCAN을 쓰면 될거 같고 모니터하며 tolerance와 윈도우(duration)을 잘 조정하여 오탐(false positive)이나 true negative를 피해야 한다.
참고: