최근 회사에서 AWS S3 비용이 늘고 있는 것을 발견하고 비용 절감은 실현한 사례를 공유한다. 말은 멋있게 했지만.. 사실 새는 돈을 막았다고 보는게 맞을거 같다. 하지만 이러한 사례, 속된 말로 클라우드에서 요금 폭탄을 맞았다 라는 이야기를 심심치 않게 들어서 다른 많은 곳에서도 겪을 수 있을 일 같다. 따라서 각자 처한 상황이나 AWS 사용 성숙도에 따라 적용해볼 수도 또는 이미 쓰고 있는 내용일 수도 있다. 이 글을 미리 한 줄로 요약하면, “S3 버킷 수명 주기 구성을 통해 불필요하게 비용이 나가는 객체를 삭제” 하는 방법에 대한 이야기이다.
참고사항
- 우리 회사에선 대부분 인프라를 온프렘 서버를 사용하여, AWS 비용이 전체 인프라 비용의 1/4 정도이다.
- 그 중 거의 절반을 S3 비용으로 쓰고 있다.
- 돈 관련한 수치는 비율이나 자릿수 정도만 밝히려고 한다(왠지 정확하게 명시하면 안될거 같다).
선요약
- 계속 AWS S3 비용이 증가하는 원인을 찾아내 월 39%~52%, 연 26% 추정치의 비용 (약 $xxK(USD), N천만원) 절감을 실현했다.
- S3 버킷 관리의 수명 주기 구성을 통해 해결했다.
- API, 인벤토리, 스토리지 렌즈 등 S3의 다양한 구성과 서비스로 버킷의 상태를 파악했다.
이야기
업무상 보여줄 보고서 같은데엔 정리해서 썼지만 여기선 실제 일어난 이야기 순서 그대로 써본다. 어느 이야기가 그렇듯 발단은 참 우연이었다. 인프라에서 AWS 비중이 높지 않아(그렇다고 생각했었다), 따로 비용 알림이 없어서 S3 비용이 늘고 있다는걸 알게된 것도 우연하게 알게 됐다.
수명 주기 구성으로 스토리지 클래스 전환
FinOps라는 단어가 어디선가 눈에 채일 때 쯤 더불어 S3의 Glacier라는 스토리지 클래스를 알게 됐다(이전까진 스토리지 클래스라는게 있는줄도 몰랐다). 회사에서 특정 S3 버킷에 백업 데이터를 많이 넣어두는 곳이 있었고, 거기에 이 스토리지 클래스를 적용하면 좋겠다 싶었다.
먼저 현황 파악을 위해 스토리지 렌즈 대시보드를 활성화 했다. 하지만 ‘고급 지표 및 권장 사항’을 활성화 하더라도 업로드 날짜 기준으로 객체를 집계할 순 없었다. 당시에 볼 수 있었던 것은 StandardIA의 객체가 절대적으로 많다 정도였다.
회사 구성원들과 논의 후 5년이 경과한 객체는 GlacierIR로 전환하기로 했다. 이미 ‘자동 이전’이란 이름으로, 업로드 후 30일 후에 Standard에서 StandardIA로 전환하는 수명 주기 구성이 있었다. 이 기존 수명 주기 구성에 위의 새 규칙을 추가했다:
resource "aws_s3_bucket_lifecycle_configuration" "lccnf_name" {
bucket = aws_s3_bucket.bucket_name.id
rule {
id = "자동 이전"
status = "Enabled"
filter {}
transition {
days = 30
storage_class = "STANDARD_IA"
}
transition {
days = 1826
storage_class = "GLACIER_IR"
}
}
}
하루 이틀 지나 스토리지 렌즈 대시보드를 확인했으나, 정말 코딱지만큼 GlacierIR로 전환되었다. 현재 기준 업로드가 5년이 지난 백업 객체가 그리 많지 않았던 것이다:
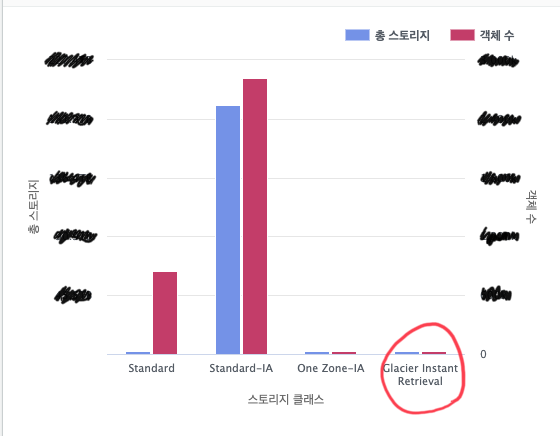
애초에 GlacierIR로 전환될 대상 객체를 정확히 파악 못했으니 그에 따른 결과일 수도 있다. 우린 베스핀글로벌이라는 AWS 파트너사에 결제 대행을 하고 있어서 S3의 일단위 요금을 볼 수 있는데 저정도의 전환으로 눈에 띄는 변화가 있을 수 없었다. 비용 감소가 큰 작업이길 기대했지만, 아쉬움만 남겨두고 이렇게 일단락 되는가 싶었다.
CloudWatch S3 지표
그러다 이 업무를 같이 봐주시던 팀장께서 이 백업 버킷 전체 크기와 객체 수가 순증하고 있다고 알려주셨다. 이전엔 S3의 지표를 볼 생각을 해본적이 없었다. ‘버킷 > 지표 > CloudWatch에서 보기’에서 최대 기간(15개월)으로 확인하니 올해부터 우상향의 그래프가 그려졌다:
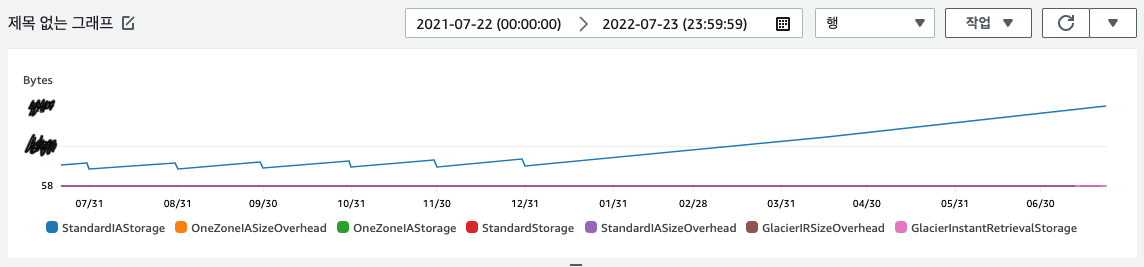
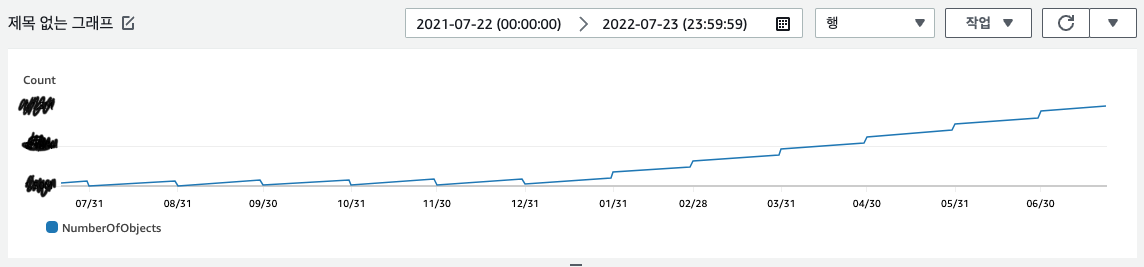
먼저 눈에 띄는 패턴은 크기 그래프에서 작년까진 월말에 뚝뚝 떨어지는 단차가 있다. 이것은 월말에 특정 기간 이상 RDB 덤프 개수를 1/4로 줄이는 배치 작업이 있어 그렇다. 객체 수 그래프에도 이런 단차가 보이고, 전체 크기는 증가하는 올해에도 패턴 자체는 이어지는 걸로 보인다(전체 객체 수는 증가하고 있다).
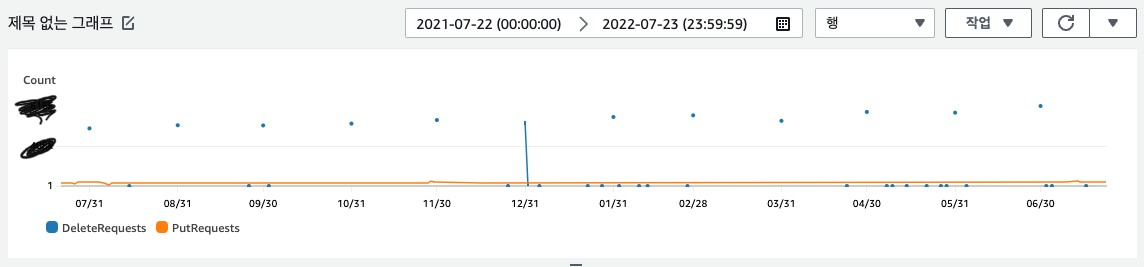
혹시 이 배치 작업이 잘 안돌고 있는 것은 아닐까? 작업 프로세스의 로그를 확인해보니 이상이 없었다. 또 CloudWatch에서 요청 지표를 확인하니 월말의 주기적인 Delete 요청 수와 전체 기간의 Put 요청 수엔 특이한 점이 없어 보였다:
그리고 결제 대행사에 S3 1년치 청구 금액을 요청하여 확인해보니 실제로 증가하고 있었다(대행사의 유료 서비스를 쓰지 않아 대시보드에서 1년치를 볼 수 없었다).
API(AWS CLI), 인벤토리 구성으로 버킷 상태 확인하기
CloudWatch가 집계하는 지표를 직접 확인하고 싶었다. 그래서 처음엔 API를 사용해서 집계해봤다. AWS CLI s3api의 list-object-v2를 이용해 다음 내용을 집계해봤다:
첫번째 스크립트는 확인하고 싶은 객체에 연/월로 접두사를 만들어 가능했다. 아마 백업, 로그 데이터는 보통 이렇게 저장할 거 같다. 스토리지 렌즈 구성하면서도 느꼈지만, S3 객체는 접두사 규칙을 잘 만들어야 활용이 좋다(잘 감이 안오면 앞에 날짜를 붙이자).
두번째 스크립트는 접두사를 좁혀 나가 최근에 수정한 객체를 찾아 아주 큰 크기 변화나 특이한 점이 있는지 보려고 했다. 하지만 접두사를 좁혀도 너무 많은 객체가 있었고, CloudWatch의 요청 지표를 보고 알 수 있는 내용보다 더 나은 점은 없었다.
세번째 스크립트를 통해 접두사 별 총 크기를 보던 중, API로 집계한 버킷의 총 크기와 CloudWatch가 가리키는 버킷의 총 크기가 다르다는 걸 알았다. API로 집계해보면 총 크기가 1xxTB인데, CloudWatch에선 5xxTB로 2~3배 정도 많게 집계되었다. 또 첫번째 스크립트로 월별 증가 추이를 봤을 때 CloudWatch에서의 그 양이 훨씬 많았다.
버킷 상태가 뭔가 이상하다고 느꼈지만 또 다른 문제가 있었다. 버킷에 객체가 많기 때문에 API 응답은 너무 느렸다. 로그를 저장하는 접두사 아래는 스크립트 실행이 시간 단위로 걸렸다.
따라서 S3 인벤토리를 구성했다. 인벤토리는 많은 List API 요청 대신 일 또는 주 단위의 배치 작업으로 객체 메타데이터를 확인할 수 있다. 모든 객체를 대상으로 결과 행에 메타데이타 크기, 마지막 수정일, 스토리지 클래스를 추가했다. 결과를 최대한 빨리 보고 싶어 일 단위로 구성하고 결제 대행사에도 왜 직접 집계한 것과 CloudWatch에 불일치가 있는지 문의했다. 아래 테라폼 코드에선 인벤토리 구성을 할 원본 버킷을 source_bucket, 인벤토리 보고서가 저장되는 대상 버킷을 target_bucket으로 치환했다:
# DATA
## target_bucket 정책을 위한 IAM 정책, 인벤토리 구성 시 기본 값(InventoryAndAnalyticsExamplePolicy) 그대로 복사
data "aws_iam_policy_document" "inventroy_and_analytics_example_policy" {
statement {
sid = "InventoryAndAnalyticsExamplePolicy"
effect = "Allow"
principals {
type = "Service"
identifiers = ["s3.amazonaws.com"]
}
actions = ["s3:PutObject"]
resources = ["${aws_s3_bucket.target_bucket.arn}/*"]
condition {
test = "StringEquals"
variable = "aws:SourceAccount"
values = ["xxxxxxxxxxxxxxxx"]
}
condition {
test = "StringEquals"
variable = "s3:x-amz-acl"
values = ["bucket-owner-full-control"]
}
condition {
test = "ArnLike"
variable = "aws:SourceArn"
values = [aws_s3_bucket.source_bucket.arn]
}
}
}
# RESOURCES
## target_bucket, 인벤토리 보고서 csv가 저장되는 버킷
resource "aws_s3_bucket" "target_bucket" {
bucket = "target_bucket"
}
## source_bucket 인벤토리
resource "aws_s3_bucket_inventory" "source_bucket_inventory" {
bucket = aws_s3_bucket.source_bucket.id
name = "EntireBucketDaily"
included_object_versions = "All"
schedule {
frequency = "Daily"
}
destination {
bucket {
format = "CSV"
bucket_arn = aws_s3_bucket.target_bucket.arn
}
}
optional_fields = [
"Size",
"LastModifiedDate",
"StorageClass"
]
}
## target_bucket 정책
resource "aws_s3_bucket_policy" "inventroy_and_analytics_example_policy" {
bucket = aws_s3_bucket.target_bucket.id
policy = data.aws_iam_policy_document.inventroy_and_analytics_example_policy.json
}
원인 파악: 버저닝 활성화와 삭제 마커
‘측정한 버킷의 크기가 CloudWatch에서 표시하는 것과 다르다’를 키워드로 검색하다 보니 이런 글을 찾을 수 있었다. 결제 대행사에서도 비슷한 답변이 왔다. 글에서 설명하는 원인은 크게 두가지이다.
- 객체 버저닝이 활성화 됐고 삭제 마커 객체가 있거나,
- 불완전한 멀티파트 업로드가 있다.
불완전한 멀티파트 집계는 API로도 쉽게 가능해서 먼저 해봤다:
❯ aws s3api list-multipart-uploads --bucket "${bucket}" | \
jq -r '.Uploads[] | [.UploadId, .Key] | @tsv' | \
head -57 | \ # 58개일 때 마지막은 현재 업로드 중인 객체인 경우가 많음, 과거것은 57개만 필터
while IFS=$'\t' read -r upload_id key; do
AWS_PAGER="" aws s3api list-parts --bucket "${bucket}" --key "${key}" --upload-id "${upload_id}"
done | \
jq 'select(has("Parts")) | .Parts[].Size' | \
paste -sd+ | bc | numfmt --to=iec
21G
- 현재 업로드 중이 아닌 멀티파트 업로드(57개)의 업로드 ID와 객체 키로(s3api list-multipart-uploads)
- s3api list-parts 요청을 하여 파트의 모든 크기를 합산했다.
불완전한 멀티파트는 개수도 적고, 21GB라는 크기는 몇백TB의 오차에 비해 아주 작기 때문에 문제되지 않아 보였다.
남은 가능성은 버킷에 객체 버저닝이 활성화 되어 있고 삭제 마커 객체가 있는 경우였다. 삭제 마커란 버킷의 객체 버저닝이 활성화된 경우 특정 버전의 객체를 영구히 삭제하지 않고 삭제할거라 마킹만 하는 것이다. 이런 삭제 마커 객체는 삭제된 것처럼 응답하지만 실제론 버킷에서 공간을 차지하고 있다.
우선 버저닝이 활성화 되어 있나 확인했더니 활성 상태였다. 누가했지? 왜 했지? 알 수 없었다. 회사에선 새로운 자원만 테라포밍하고 있어서, 만든지 오래 된 이 버킷의 버저닝 역시 테라폼 자원으로 관리하고 있지 않았다. 그저 올해 초쯤에 버저닝이 활성화 됐다고만 추정할 수 있었다.
따라서 앞으로는 코드로 관리, 추적할 수 있게 객체 버저닝 자원(aws_s3_bucket_versioning)을 테라포밍했다. 그런데 versioning_configuration.status 인자는 한번 활성화(Enabled)된 자원을 비활성화(Disable) 할 수 없게 되어 있다(S3의 제약사항인것 같다). 그래서 비활성화 대신 일시 중지(Suspend) 해주었다.
객체 버저닝은 한시름 놨지만(?) 이미 만들어진 삭제 마킹된 객체를 파악할 필요가 있다. 마침 인벤토리 보고서 CSV가 생성됐다. 위에서 적은 추가 메타데이터를 포함해 컬럼은 다음과 같다:
❯ cat manifest.json | jq -r .fileSchema
Bucket, Key, VersionId, IsLatest, IsDeleteMarker, Size, LastModifiedDate, StorageClass
추가한 메타데이터 외에 기본으로 포함하는 정보에 버전(VersionId)과 삭제 마커 여부가 있었다(IsDeleteMarker). 이 CSV를 파싱해서 집계해보니 약 38%가 삭제 마킹된 객체였고, 그 총 크기가 CloudWatch의 버킷 총 크기와 API로 집계했던 것의 차이, 약 3xxTB 정도 됐다. 문제의 원인을 찾았다.
삭제 마킹 됐기 때문에 이 백업 객체들은 활용되고 있지 않았을 것이다. 영구히 삭제해도 되는지 검토하고 쓸데 없는 S3 비용을 줄이기 위해 삭제하기로 했다.
* s3api list-object-versions를 사용해 삭제 마킹 객체를 포함한 모든 버전 객체 데이터를 가져오는 것도 동시에 진행했다. 하지만 요청 응답만 거의 하룻밤이 걸려 추천하지 않는다. 그냥 인벤토리를 쓰자.
해결: 다시 수명 주기 구성
38% 정도의 삭제 마킹 객체도 수가 백만단위였다. 이걸 API가 아닌 SDK로 지우는 것도 비효율적으로 보였다. 다행히 수명 주기 구성의 만료 정책에 삭제 마킹 객체를 지우는 규칙이 있다. 이 규칙을 사용해 하루만에 많은 불필요한 객체, 삭제 마킹 객체와 이전 버전 객체를 삭제할 수 있었다. 위에서 스토리지 클래스 전환 때문에 먼저 만든 수명 주기 구성에 규칙(rule)을 추가했다:
resource "aws_s3_bucket_lifecycle_configuration" "lccnf_name" {
bucket = aws_s3_bucket.bucket_name.id
# ... 자동 이전 룰 생략
rule {
id = "DeleteOldVersionObjects"
status = "Enabled"
filter {}
noncurrent_version_expiration {
noncurrent_days = 1
}
expiration {
expired_object_delete_marker = true
}
}
}
expiration.expired_object_delete_marker 인자는 days와 같이 쓰지 않도록 주의하자. date, days와 같이 쓰면 expired_object_delete_marker는 무시되고, 현재 버전 객체가 해당 날짜에 만료 되어 버린다.
기대 효과
규칙 적용 다음 날 속 시원하게 버킷 크기가 줄어 들었다:
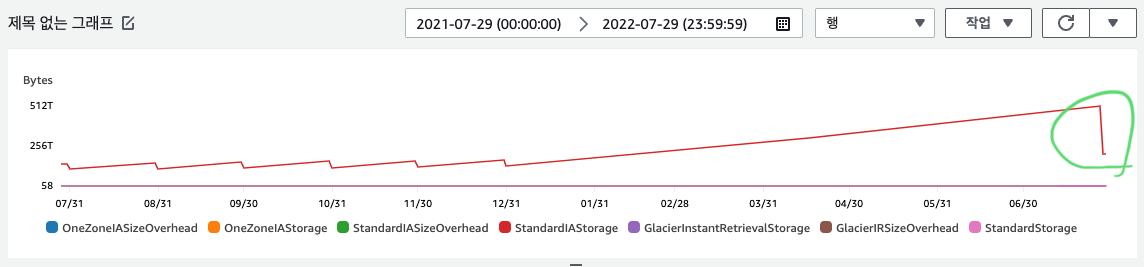
StandardIA가 절대 다수, 크기의 객체라 위처럼 그려졌다.
그리고 일 요금도 거의 40% 정도 줄었다(결제 대행사 대시보드에 S3만 따로 일 단위 비용을 볼 수 있다). 월 그리고 연 단위로 절감할 것으로 기대되는 비용을 계산해봤다. 대략적인 S3의 사이즈 증가를 적용해서 위 작업을 하지 않았을 때와 비교하니 월 단위로는 약 39~52%, 연 단위로는 26% 정도의 비용이 감소할걸로 기대된다.
월과 연 단위 비율 차이가 큰 것은 이미 올해가 많이 지났다는 뜻이기도 하다. 그래서 앞서 절감, 최적화 보단 새는 돈을 막았다는 표현을 썼다. 하지만 이 작업을 통해 xxK 달러(USD), 오차를 크게 잡아도 천만원 단위의 비용 절감이 된다고 생각하니 짜릿했다.
임팩트가 커서 보람과 성취도 역시 크게 느껴졌다. 또 개인적으론 AWS를 잘 모른다 생각했고, 이미 만들어진 인프라에 수정하는 일이 적어 이해도가 낮다고 생각했는데 이 작업을 계기로 AWS에 대한 자신감도 생겼다. 되려 스토리지 클래스 전환으로 비용 최적화를 꾀했던 것은 아직 눈에 띄는 성과가 없지만, 그런 관심이 이어져 다른 큰 문제를 해결하게 됐다.
더 할 일
설명한 것처럼 이번 문제는 우연히 알게 됐다. 앞으로 이렇게 불필요한 비용이 발생하지 않기 위해 해야할 것들이 있다.
S3 모니터를 강화해야 한다. 버킷의 크기, 객체 수 그리고 비용이 이상한지 또는 크게 증가하는지 미리 알 수 있어야 한다. 앞서 이야기한 듯 CloudWatch를 사용하려면 서비스 할당량 증가 신청을 해야해서 왠지(?) 돈이 많이 들 것 같다. API는 너무 느려서 사용하기에 비효율적이다. 실시간으로 지표를 볼 필요가 없으니 인벤토리를 활용하는 것도 좋아 보인다. 스토리지 렌즈 대시보드는 계속 활성화 시켜놨다. 활성화 된 날짜 이후의 지표만 집계된다. 또는 결제 대행사의 서비스나 도움을 받는 방법도 있을 것이다. 뭐가 더 비용 효율적인지 고민해봐야 한다.
개인적으론 테라폼 공부를 시작했다. 인프라를 코드로 관리해야 할 필요성과 단순하게 테라폼으로 AWS 서비스를 구성하는 재미를 동시에 느꼈다. 그런데 코딩 하다보니 문서보고 자원을 수평 확장(=복붙)하는 느낌만 들어 더 체계적으로 관리할 필요가 있겠다고 느꼈다.
FinOps도 공부해보려 한다. 이 작업 전까지는 인적 비용 또는 잠재적인 비용만, 잘 측정하지 못한 채, 고려했던 것 같다. 하지만 클라우드 환경에서 발생하는 비용은 바로 액수로 환산되어 아주 명확하다. 이번엔 운 좋게 꽤 큰 비용을 줄일 수 있는 곳에 관심을 가져 큰 효과를 봤다. FinOps라는 개념에 계속 관심을 갖고 공부하면 이런 짜릿한 경험이 많이 생길 것 같다. ‘FinOps - 클라우드 비용 최적화’라는 오픈 채팅에 가입해 알게 된 사실도 몇가지 글에 녹아 있다. 커뮤니티에서 꾸준히 정보와 자극을 받으며 공부할 계획이다.
정리
앞에 이미 글에 대한 선요약도 있으니, 여기선 글 정리 대신 이 작업을 하며 몇가지 느낀 점을 남긴다:
- 버킷 크기가 비정상적으로 증가한다면 (불필요한) 버저닝과 삭제 마킹 객체가 있는 것을 의심해볼 수 있다.
- 버킷 아래 접두사를 잘 정의하는 것은 여러 구성에서 유리하다.
- 보통 연/월(/일)의 날짜 구성을 따르면 좋다.
- S3 상태, 지표를 확인하기 위한 여러 구성과 서비스를 적극적으로 이용하자.
- CloudWatch
- 인벤토리
- 스토리지 렌즈
- S3 비용 절감, 최적화를 위해 수명 주기 구성을 잘 쓰자.